flowchart LR
%% Input Layer
I1((I1)):::inputStyle
I2((I2)):::inputStyle
I3((I3)):::inputStyle
B1((Bias)):::biasStyle
%% Hidden Layer
H1((H1)):::hiddenStyle
H2((H2)):::hiddenStyle
H3((H3)):::hiddenStyle
B2((Bias)):::biasStyle
%% Output Layer
O1((O1)):::outputStyle
O2((O2)):::outputStyle
%% Connections
I1 -->|w11| H1
I1 -->|w12| H2
I1 -->|w13| H3
I2 -->|w21| H1
I2 -->|w22| H2
I2 -->|w23| H3
I3 -->|w31| H1
I3 -->|w32| H2
I3 -->|w33| H3
B1 -->|b1| H1
B1 -->|b2| H2
B1 -->|b3| H3
H1 -->|v11| O1
H1 -->|v12| O2
H2 -->|v21| O1
H2 -->|v22| O2
H3 -->|v31| O1
H3 -->|v32| O2
B2 -->|b4| O1
B2 -->|b5| O2
%% Styles
classDef inputStyle fill:#3498db,stroke:#333,stroke-width:2px;
classDef hiddenStyle fill:#e74c3c,stroke:#333,stroke-width:2px;
classDef outputStyle fill:#2ecc71,stroke:#333,stroke-width:2px;
classDef biasStyle fill:#f39c12,stroke:#333,stroke-width:2px;
%% Layer Labels
I2 -.- InputLabel[Input Layer]
H2 -.- HiddenLabel[Hidden Layer]
O1 -.- OutputLabel[Output Layer]
style InputLabel fill:none,stroke:none
style HiddenLabel fill:none,stroke:none
style OutputLabel fill:none,stroke:none
Week 03
Basics of Neural Networks (Part 2)
LLMs in Lingustic Research WiSe 2024/25
23 Oct 2024
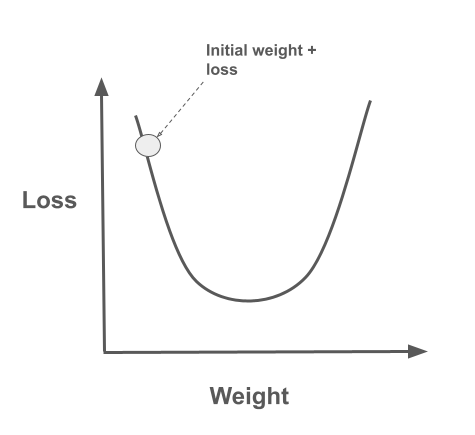
- X-axis (Weight): Represents the value of the model parameter being optimized.
- Y-axis (Loss): Represents the value of the loss function being minimized.
- The goal is to find the value of the model parameter that minimizes the loss function.
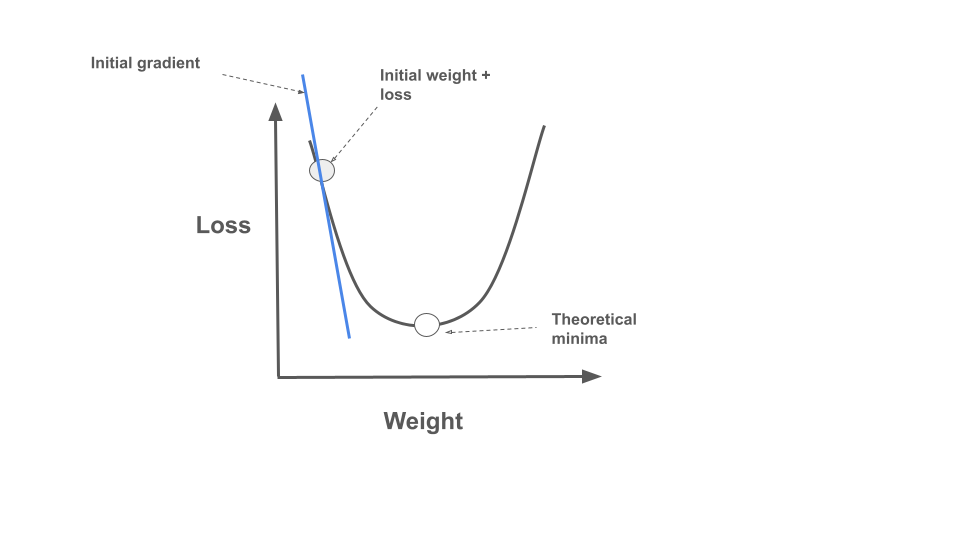
- The process starts at an initial weight with a corresponding loss, marked as “Initial weight + loss” on the graph
- Gradient: The algorithm calculates the gradient (slope) at the current position. This gradient indicates the direction of steepest ascent.
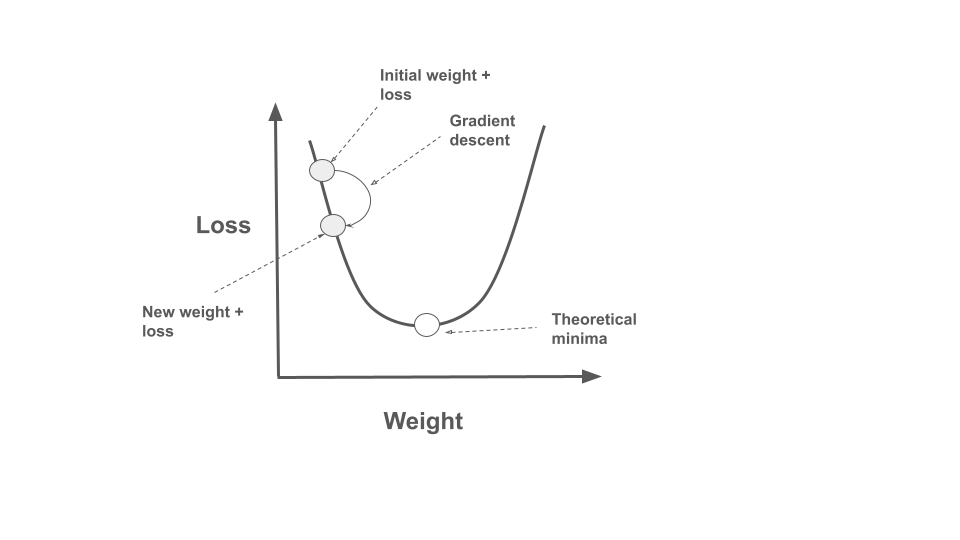
- The model then takes a step in the opposite direction of the gradient, as we want to minimize the loss.
- This is why it’s called gradient descent - we descend along the gradient.
- The “New weight + loss” point on the graph shows an intermediate step in this process, where the loss has decreased compared to the initial position.
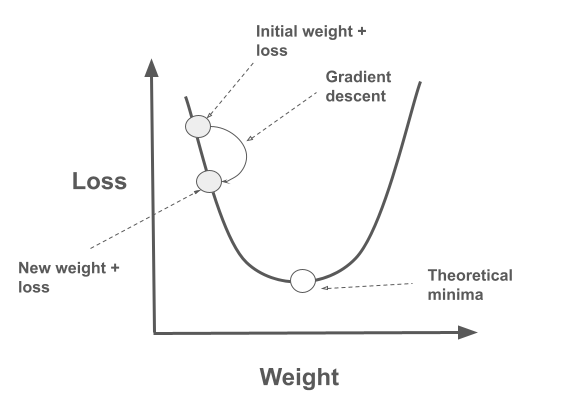
- As the algorithm progresses, it should ideally approach the bottom of the curve, labeled as “Theoretical minima” in the image.
- The algorithm may not always reach the exact theoretical minima due to factors like step size (learning rate) and the complexity of the loss landscape.
- But, it typically converges to a point close enough to be practically useful for model optimization.